




AIは今や流行語となり、しばしばデータセンターや大規模言語モデル(LLM)を支える強力なコンピューティングプラットフォームと結び付けられています。データセンターレベルでのAIのスケーリング(学習)にはGPUが欠かせませんでしたが、IoTデバイスやビデオ監視カメラ、エッジコンピューティングシステムといった電力制約のある環境でAIを展開するには、まったく異なるアプローチが必要です。業界は現在、分散型かつ低消費電力のアプリケーションに特化した、より効率的な計算アーキテクチャーやAIモデルへとシフトしつつあります。
今後は、数百万台、あるいは数十億台にも及ぶエンドポイントが、AI処理のためにクラウドへ接続するだけの存在からどのように進化していくべきかを改めて考える必要があります。これらのデバイスは、真にAIを搭載したエッジシステムへと変貌し、1ワットあたりの演算性能(TOPS/W)という電力効率の観点から、オンデバイスでの推論処理を最大限の効率で実行できるようにならなければなりません。
リアルタイムAIコンピューティングの課題
AIの基盤モデルが大規模化するにつれ、インフラコストやエネルギー消費が急激に増加しています。この理由から、増大する生成AIの需要に対応するための、データセンターが備えるべき性能に注目が集まっています。一方で、エッジでのリアルタイム推論においては、データが生成される場所――つまりデバイスそのもの――にAIアクセラレーションを近づけることが引き続き強く求められています。
エッジでAIを運用することには、新たな課題が伴います。もはや、1秒あたりの演算性能(TOPS)といった演算能力を単に確保するだけでは不十分なのです。各ユースケースにおける消費電力やコストの厳しい制約の中で、メモリパフォーマンスも同時に考慮する必要があります。こうした制約から、有効なAIエッジソリューションでは、コンピューティングとメモリが同じくらい重要な構成要素になりつつあるという、新たな現実が浮かび上がります。
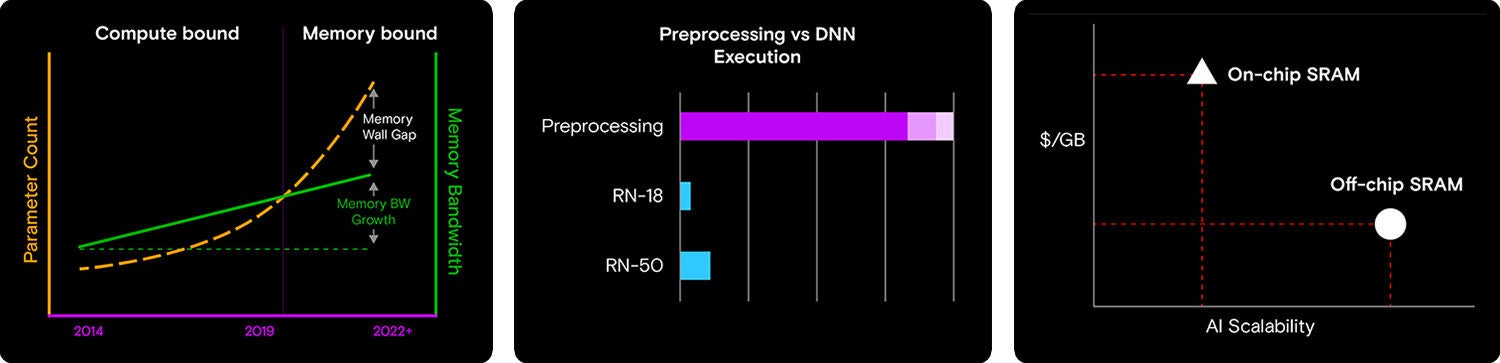
より多くの入力とタスクを処理可能な高度化したAIモデルが開発されるにつれ、モデルのサイズと複雑性が高まっていき、大量のコンピューティングパワーが要求されるようになります。TPUとGPUは、この成長に見合うペースで進歩してきましたが、メモリ帯域幅とパフォーマンスは、同じように進歩してきたとは言えません。そのため、ボトルネックが生じます。より大量のデータをGPUが処理できたとしても、メモリシステムによる供給が追い付きません。これは、AIシステムの設計における、バランスの取れたコンピューティングとメモリの必要性を物語る、新たな課題です。
組み込みAIの普及とともに、メモリが極めて重要な考慮事項になっています。

産業用コンピューティングへの生成AIの統合がますます進んでいます。
モデルの複雑化やコンピューティングパワーの向上にもかかわらず、組み込みのエッジAIシステムでメモリ帯域幅がボトルネックとなり、パフォーマンスが制限されています。
もう1つの重要な考慮事項は、推論には移動中のデータが関与することです。つまり、前処理されたキュレーション済みのデータを、ニューラルネットワーク(NN)に取り込む必要があります。同様に、量子化とアクティベーションがNNを通過した後は、全体的なAIパイプラインにとって、後処理も重要になります。自動車に500馬力のエンジンが搭載されているにもかかわらず、燃料には低オクタン価ガソリンを使用し、タイヤをスペアタイヤにしているようなものです。どんなにエンジンが強力でも、自動車全体のパフォーマンスは、システムの最も弱いコンポーネントによって制限されます。
3番目の考慮事項として、SoCにNPUやアクセラレーター機能が含まれていても、サンドボックスの一部分として小型のRAMキャッシュが追加されると、これらのマルチドメインプロセッサーのコストによって部品表(BOM)が増大し、柔軟性が制限されます。
最適化された専用のASICアクセラレーターの価値は、どんなに強調してもしすぎることはありません。これらのアクセラレーターは、ニューラルネットワークの効率性を高めるだけでなく、広範囲のAIモデルへの対応に柔軟性をもたらします。ASICアクセラレーターのもう1つのメリットは、最良のTOPS/Wを提供するよう調整されていて、低い消費電力、良好な熱範囲、幅広い用途がメリットとなるエッジアプリケーションに適している点です。具体的には、自律型の農業機器、ビデオ監視カメラ、自律型の倉庫用モバイルロボットなどがあります。
コンピューティングとメモリの相乗効果
エッジプラットフォームに統合されたコプロセッサーによって、リアルタイムの深層学習推論タスクが、低い消費電力と高いコスト効率で実行可能になります。これらは、広範囲のニューラルネットワーク、ビジョン変換モデル、LLMに対応します。
このようなテクノロジーの相乗効果の代表例が、HailoのエッジAIアクセラレータープロセッサーと、マイクロンの低消費電力DDR(LPDDR)メモリの組み合わせです。これらはコンピューティングとメモリの適切な組み合わせを提供しながら、厳しく制限されたエネルギーおよびコスト/予算の範囲内に収まる、バランスの取れたソリューションであり、エッジAIアプリケーションに最適です。
メモリおよびストレージソリューションの最有力プロバイダーであるマイクロンのLPDDRテクノロジーは、電力効率を犠牲にすることなく、高速・高帯域幅のデータ転送を実現し、リアルタイムデータ処理におけるボトルネックを排除します。スマートフォン、ノートパソコン、車載システム、産業用デバイスで広く利用されているLPDDRは、最新のAIアクセラレーターとペースを合わせるため、広いI/O帯域幅と高いピン速度を必要とする組み込みAIアプリケーションに、とりわけ適しています。
たとえば、LPDDR4/4X(低消費電力DDR4 DRAM)およびLPDDR5/5X(低消費電力DDR5 DRAM)は、前世代と比べて著しく高いパフォーマンスを提供します。LPDDR4は、最大x64のバス幅で1ピンあたり最大4.2 Gbits/秒の速度に対応します。マイクロンの1ベータLPDDR5Xでは、このパフォーマンスが2倍になり(1ピンあたり最大9.6 Gbits/秒)、電力効率はLPDDR4Xと比べて20%向上しています。こうした進歩は、需要が高まりつつあるエッジAIに対応するうえで極めて重要です。エッジAIには、速度とエネルギー効率の両立が欠かせません。
Hailoは、マイクロンがコラボレーションを行っている有力なAIシリコンプロバイダーの1社です。Hailoは、エッジデバイス上で高性能な深層学習アプリケーションを実行可能にする、独自に設計した画期的なAIプロセッサーを提供しています。Hailoプロセッサーは、エッジにおける新時代の生成AI向けに調整されています。これと並行して、広範囲に及ぶAIアクセラレーターとビジョンプロセッサーにより、認知やビデオ拡張にも対応します。

たとえば、最大40 TOPSで動作するHailo-10H AIプロセッサーは、数え切れないほど多くの用途に対応するAIエッジプロセッサーです。Hailoによると、Hailo-10H独自の強力かつスケーラブルな構造によるデータフローアーキテクチャーは、ニューラルネットワークのコア特性を活用しています。そのため、大幅にコストを削減しながら、従来のソリューションよりも効率的かつ効果的に、エッジデバイス上で深層学習アプリケーションをフルスケールで実行できます。
ソリューションの運用
AIビジョンプロセッサーは、スマートカメラに最適です。Hailo-15 VPUシステムオンチップ(SoC)は、HailoのAI推論機能と先進的なコンピュータービジョンエンジンの組み合わせにより、優れた画像品質と高度な動画アナリティクスを生成します。このビジョン処理ユニットのAI能力を利用して、AI駆動の画像拡張と、複数の複雑な深層学習AIアプリケーションをフルスケールで効率的に実行することができます。

さまざまな用途において厳格なテストを受けたマイクロンの低消費電力DRAM(LPDDR4X)と、HailoのAIプロセッサーを組み合わせることで、幅広いアプリケーションに対応できます。温度やパフォーマンスに過酷な条件が要求される産業用および車載用アプリケーションから、エンタープライズシステムの厳密な仕様まで。マイクロンのLPDDR4Xは、電力効率を犠牲にせずに高性能・高帯域幅データレートを提供し、HailoのVPUに最適です。
最強の組み合わせ
AI対応デバイスを利用するユースケースが増えるにつれ、何百万台もの(さらには、何十億台もの)エンドポイントを、単なるクラウドエージェントではなく、最低のTOPS/Wでオンプレミス推論に対応できる、真のAI対応エッジデバイスとして進化させる方法を開発者が考察する必要に迫られます。エッジにおけるAIを加速させるためにゼロの状態から設計されたプロセッサーと、低消費電力で信頼性の高い高性能なLPDRAMにより、さらに多くのエッジAIアプリケーションの開発が可能になります。
